| Python ライブラリリファレンス |
| Python ライブラリリファレンス |
audioopモジュールにはサウンドデータに対する便利な操作が定義されています。
このモジュールは、Python文字列で保存された、8、16、32ビットサイズの符合付き整数型からなるサウンドデータを処理します。
このデータはalとsunaudiodevモジュールで使用されるのと同じフォーマットです。
特に断わらない限り数値項目は整数です。
このモジュールはu-LAWとIntel/DVI ADPCMエンコードをサポートしています。
複雑な操作のうちいくつかは16ビットのサンプルに対してのみ働きますが、それ以外は常にサンプルサイズ(バイト数)を操作のパラメータとして渡します。
このモジュールは以下の変数と関数を定義しています:
| fragment1, fragment2, width) |
widthはサンプルサイズのバイト数で、1、2、4のうちのどれかです。
2つのデータは同じサンプルサイズでなければなりません。
| adpcmfragment, width, state) |
(sample, newstate)のタプルを返します。
| adpcmfragment, width, state) |
| fragment, width) |
| fragment, width) |
| fragment, width, bias) |
| fragment, width) |
| fragment, reference) |
rms(add(fragment, mul(reference, -F)))が最小となるようなFを返します。つまり、referenceに掛けるとfragmentにできるだけ一致するような値を返します。
fragmentとreferenceは両方とも2バイトのサンプルでなければなりません。
このルーチンの実行に要する時間はlen(fragment)に比例します。
| fragment, reference) |
(offset, factor)のタプルを返します。offsetは最適な一致箇所が始まるfragmentのオフセット値(整数)で、factorはfindfactor()で返される数値(浮動小数点数)です。
| fragment, length) |
rms(fragment[i*2:(i+length)*2])が最大となるようなiを返します。
データは2バイトのサンプルでなければなりません。
このルーチンの実行に要する時間はlen(fragment)に比例します。
| fragment, width, index) |
| fragment, width, newwidth) |
| fragment, width, state) |
stateはエンコードの情報を含んだタプルです。
(adpcmfrag, newstate)のタプルを返します。newstateは次にlin2adpcm()を呼び出す時に渡さなければなりません。
最初の呼び出しではstateとしてNoneを渡します。
adpcmfragはADPCMでコード化された、バイト当たり2つの4ビット値です。
| fragment, width, state) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width) |
| fragment, width, factor) |
| fragment, width, nchannels, inrate, outrate, state[, weightA[, weightB]]) |
stateは変換の情報を含むタプルです。
(newfragment, newstate)を返します。
newstateは次にratecv()を呼び出す時に渡さなければなりません。
最初の呼び出しではstateとしてNoneを渡します。
引数weightAとweightBはシンプルなデジタルフィルターのためのパラメータで、デフォルトではそれぞれ1、0です。
| fragment, width) |
| fragment, width) |
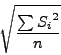
| fragment, width, lfactor, rfactor) |
| fragment, width, lfactor, rfactor) |
| fragment, width) |
mul()やmax()はモノラルとステレオの区別をつけずに、全サンプルを等しく扱います。 これが問題なら、初めにステレオデータを2つのモノラルデータに分割して、あとで結合するといいでしょう。 どうしたらいいか、例を挙げます。
def mul_stereo(sample, width, lfactor, rfactor):
lsample = audioop.tomono(sample, width, 1, 0)
rsample = audioop.tomono(sample, width, 0, 1)
lsample = audioop.mul(lsample, width, lfactor)
rsample = audioop.mul(rsample, width, rfactor)
lsample = audioop.tostereo(lsample, width, 1, 0)
rsample = audioop.tostereo(rsample, width, 0, 1)
return audioop.add(lsample, rsample, width)
もしネットワークパケットを構築してADPCMフォーマットを使って、プロトコールの説明なしにしたいなら(つまりパケットの損失を我慢できるなら)、データだけでなくstateも送信するべきです。 注意してほしいのは、(コーダーによって返される)最後のstateでなく、initialのstate(lin2adpcm()に渡す引数)をコーダーに渡すことです。 もしバイナリでstateを保存するのにstruct.struct()を使いたいなら、最初の要素(最初の値)を16ビットで、2番目の要素(前のサンプルとの差)を8ビットでコード化します。
ここのADPCMコーダーは他のADPCMコーダーに対しては試していません。 それぞれの標準のものとの間で操作できない場合は、私が仕様を誤解していることも十分あり得ます。
find*()ルーチンは、一見、滑稽に見えるかもしれません。 これらは最初、エコーを取り消すためのものでした。 これを合理的に速く実行するには、出力サンプルのレベルの一番大きい部分を取り出し、その場所の入力サンプル内での位置をみつけ、入力サンプルから出力サンプル全体を減算します:
def echocancel(outputdata, inputdata):
pos = audioop.findmax(outputdata, 800) # 1/10秒
out_test = outputdata[pos*2:]
in_test = inputdata[pos*2:]
ipos, factor = audioop.findfit(in_test, out_test)
# Optional (for better cancellation):
# factor = audioop.findfactor(in_test[ipos*2:ipos*2+len(out_test)],
# out_test)
prefill = '\0'*(pos+ipos)*2
postfill = '\0'*(len(inputdata)-len(prefill)-len(outputdata))
outputdata = prefill + audioop.mul(outputdata,2,-factor) + postfill
return audioop.add(inputdata, outputdata, 2)
| Python ライブラリリファレンス |